[JAVA] Java 对象的内存分配:Heap OR Stack
Java 有句古话:一切皆对象。又众所周知:Java 对象都是在堆上创建的。可得:Java 都是分配在堆中。ok,本文完。
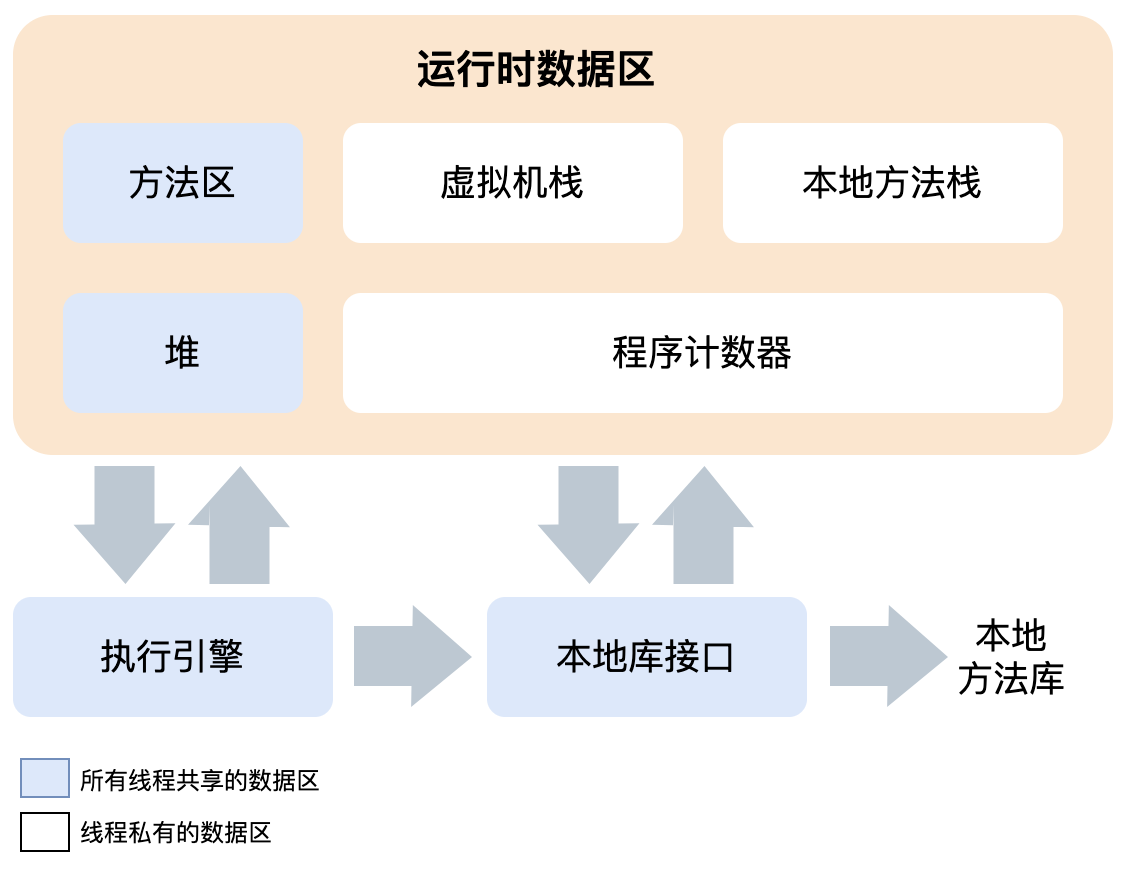
JVM 运行时内存区域划分
说到 JVM 的运行时数据区域,可能就会想到堆和栈。虽然这样的划分有些笼统,但也算不上错,确实可以大致划分为这两大区域。
从数据隔离上区分,堆一般可以看作是所有线程共享的区域,而栈空间则是线程私有的,较细化的划分如下图:
Java 堆 (Java Heap)
Java 堆,又叫 GC 堆,是 JVM 管理的内存中最大的一块。绝大多数的对象实例都在这里分配内存,前面提到那句”众所周知”的话,其实出自《Java 虚拟机规范》,原文:
The heap is the runtime data area from which memory for all class instances and arrays is alloacated.
所有的对象实例和数组都应当在堆上分配。
Java 堆是线程共享的,可通过参数 -Xmx 和 -Xms 扩展。默认大小一般是物理内存的 1/64 到 1/4,server 模式下有所不同。如果在 Java 堆中没有内存完成实例分配,并且堆也无法再扩容时,JVM 将会抛出 OutOfMemoryError 异常。官方文档描述:Default Heap Size (JDK8)
方法区 (Method Area)
方法区又叫非堆(Non-Heap),就是为了和堆区分开。因为很多人会把 HotSpot 之前的”永久代”直接理解为方法区(只是因为 HotSpot 用永久代来实现方法区),《Java 虚拟机规范》也有描述:
Although the method area is logically part of the heap, simple implementations may choose not to either garbage collect or compact it.
尽管所有的方法区在逻辑上是属于堆的一部分,但一些简单的实现可能不会选择去进行垃圾收集或者进行压缩。
方法区和堆一样是线程共享的,用于储存已被虚拟机加载的类型信息、常量、静态变量(JDK7及之后的版本,HotSpot 已经把字符串常量池和静态变量移至堆中,JDK8以后彻底放弃永久代,改用本地内存实现的元空间(MetaSpace)代替)、即时编译器编译后的代码缓存等数据。运行时常量池也属于方法区。
如果方法区无法满足新的内存分配需求时,将抛出 OutOfMemoryError 异常。
虚拟机栈 (Virtual Machine Stack)
虚拟机栈,就是我们常说的”栈”。每个方法被执行的时候,都会同步创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每个方法被调用到执行完毕的过程,就对应一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表里就是我们编码时在方法中定义的基本类型和对象引用,注意对象引用并不是指对象本身,可以理解为指向对象实际存储位置的一个指针。
虚拟机栈是线程私有的,生命周期和线程相同。
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常;如果 Java 虚拟机栈容量可以动态扩展,当栈扩展时无法申请到足够的内存会抛出 OutOfMemoryError 异常(不过 HotSpot 的栈容量是不可以动态扩展的,所以在 HotSpot 上只要线程申请栈空间成功了就不会有 OOM,但是如果申请时就失败,仍然是会出现 OOM 异常的)。
本地方法栈 (Native Method Stacks)
本地方法栈和虚拟机栈的作用基本相同,区别是虚拟机栈为虚拟机执行 Java 方法服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。但在我们现在常用的 HotSpot 虚拟机中,其实已经把两者合并了。
程序计数器 (Program Counter Register)
程序计数器和虚拟机栈一样也是线程私有的,它只占很小一块内存(32位 JVM 中占 4 byte,64位 JVM 中占 8 byte),而且是唯一一个不会发生 OutOfMemoryError 的区域。
它可以看作是当前线程执行的字节码的行号指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器。
通过一个简单代码抽象的理解一下编码中对象的内存分配:
void m() {
ClassA a = new ClassA();
...
}
// ClassA: 类的定义,存放在方法区
// a: 局部变量的引用,存放在虚拟机栈的局部变量表中
// new ClassA(): 对象实例本身,存放在 Java 堆中 (先不考虑逃逸分析)
栈上分配
我们应该知道,Java 程序在运行时 JVM 会通过即时编译器 (Just In Time Compilation, JIT) 将热点代码尽可能的优化后编译为本地机器码,从而提高执行效率。
栈上分配 (Stack Allocations) 就是一种基于逃逸分析技术从而更加灵活使用栈内存的即时编译器优化技术。(需要注意的是,严格来说目前 HotSpot 并没有使用这项优化,只使用了逃逸程度要求更高的标量替换,但这其实也是属于栈上分配的另一种形式。)
逃逸分析 (Escape Analysis)
逃逸分析的基本原理其实很简单:分析对象的动态作用域,当一个对象在方法里被定义后,它可能会被外部方法所引用。比如作为返回值传递到外部或其他方法中,这种就是方法逃逸;还可能被其他线程访问到,比如赋值给可以被其他线程访问的实例中,这种就是线程逃逸。
对象由高到低的逃逸程度是:线程逃逸 » 方法逃逸 » 不逃逸
标量替换 (Scalar Replacement)
数据可以根据是否可再分解分为标量和聚合量。如 JVM 中的原始基本数据类型 (八大基本类型和 references 类型等) 就是标量,而对象就是可以继续分解的聚合量。
标量替换就是通过逃逸分析确定一个对象不会发生方法逃逸后,再将其拆散为基本类型来访问,就可以实现不把这个对象存放在堆中而是存在栈中。(前面提到过方法体中的局部基本类型变量是存放在虚拟机栈的局部变量表中的)
根据逃逸分析还有另一项优化就是同步消除 (Synchronization Elimination):当确认一个变量不会发生线程逃逸后,这个变量就肯定是线程安全的了,如果代码中对它有实施的同步操作也就可以直接消除掉。
堆外分配
实际上,JVM 运行时对象不光可以分配在堆或栈,还有第三个选择就是堆外分配 (Off-Heap Allocation)。这个”堆外”不是指”Java 堆之外”,而是整个运行时数据区以外。是系统分配的直接内存 (Direct Memory),不受 Java 堆的大小限制。
我们常用的 JDK 1.4 加入的 NIO 类库就是使用这一机制,避免 Java 堆和直接内存来回交互,提供高效的 I/O 操作。
NIO 核心类 ByteBuffer 中的 allocateDirect() 方法进行内存分配。实现是通过实例化非公开类 DirectByteBuffer ,内使用 UNSAFE.allocateMemory() 完成。
// java.nio.DirectByteBuffer
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer {
...
// Primary constructor
DirectByteBuffer(int cap) { // package-private
...
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
...
try {
base = UNSAFE.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
UNSAFE.setMemory(base, size, (byte) 0);
...
}
...
}
TLAB 分配
为了提高多线程环境下的对象分配性能,JVM 提供了线程本地分配缓存 (TLAB - Thread Local Allocation Buffer)。但它是从 Java 堆中划分出来的线程私有的空间,本质还是属于堆分配。
这里提一下是因为机制比较常见,可能会让人误以为是一种和栈上分配一样的特殊内存分配机制。